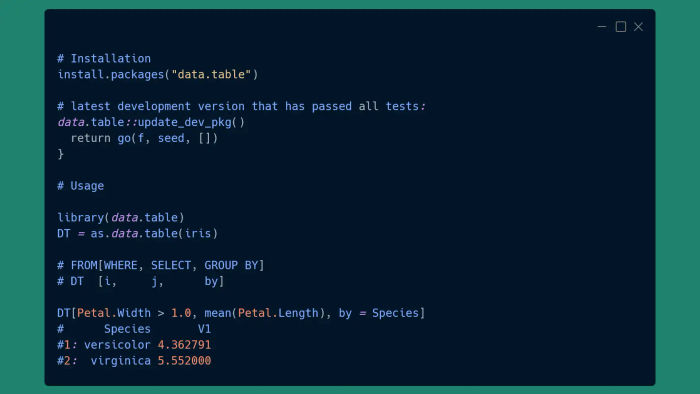
O pacote data.table é um dos pacotes de manipulação de dados mais rápido, atualmente ele é mais rápido até que o pandas e dplyr 1. A sintaxe de um data.table é dt[i, j, by], em que:
- i é utilizado para amostrar linhas
- j é utilizado para amostrar colunas
- by é utilizado para amostrar grupos, igual ao GROUP BY do SQL
Você pode ler em voz alta como2:
Pegue
dt, amostra/reordene as linhas usandoi, então calculej, agrupando porby.
Um data.table também é um data.frame e todas as manipulações de dados básicas que você pode usar em um data.frame se aplica a um data.table. Como ncol(), nrow(), names(), summary(). Mas ele não para por aí, por exemplo data.table possui uma variável especial .N que é um integral que contains os números das linhas no grupo. Se você usar dt[.N] você verá a última linha do seu data.table.
Outra coisa interessante do data.table é que se você quiser filtrar/amostrar uma coluna, você não precisa utilizar df$x[df$x == 1] você pode simplesmente usar dt[x == 1] o que torna o seu código mais limpo e fácil de ler.
Você também tem a possibilidade de utilizar operadores especiais como: %like%, %in% e %between%. Estes operadores funcionam como operadores de SQL, LIKE, IN, e BETWEEN, respectivamente.
Se você está familiarizado com SQL tem uma coisa que esse pacote oferece que irá chamar a sua atenção. No inglês se chama chaining (acorrentar), que permite a você a fazer uma sequência de operações em um data.table, você apenas precisa utilizar dt[][] e acorrentar múltiplas operações com “[]”.
Mas este não são todos os operadores, com := você pode alterar dados sem fazer uma nova cópia na memória.
Caso queira começar a usar o pacote eu sugiro que use a cheatsheet (folha de referência/colinha). É extramente útil caso já tenha um conhecimento básico sobre data.frames.